Quantifying Distraction with Computer Vision
My research into using computer vision to measure subconscious distractions.

We live in a distracting world. Many of us are aware of the dangers associated with phone addiction; even less of us try to combat these dangers using so-called “productivity tech,” such as app blockers and time limits. I’ve tried my fair share of these technologies, and while I’ve noticed some success using them, I also realized I wanted something a bit different. All these apps make the assumption that the user has already identified their distracting habit and intentionally wants to block it out. But what about the stage before that, when you aren’t even aware of what’s distracting you? I want to target those subconscious distractions that silently erode your attention span. With that idea in mind, I tried my hand at making a new kind of productivity app.
When I began thinking on this idea, the first thing that came to mind was to create an app that monitors a user through their webcam and computationally calculates their level of focus through their observable behavior. But when I began doing research, I quickly realized that focus is quite difficult to quantify even if we account for internal neurological factors, let alone with only physical metrics. I then tweaked my idea to focus on quantifying external and tangible sources of distraction rather than one’s own internal focus.
Previous research to tackle this problem has tried to measure distraction using just facial features. I expand on this idea in my work by accounting for three subconscious habits as metrics for tracking distraction. Each metric has its own score, and I also came up with a formula for an overall “focus” score.
Habit #1: Poor Posture
Aside from consequences to health, poor posture has a negative impact on a person’s cognitive processing, especially in the long run. To measure a user’s posture, I employed the MediaPipe Pose Landmarker task, a machine learning model from Google that can detect and annotate important landmarks on a human body (arms, shoulders, eyes, etc.).
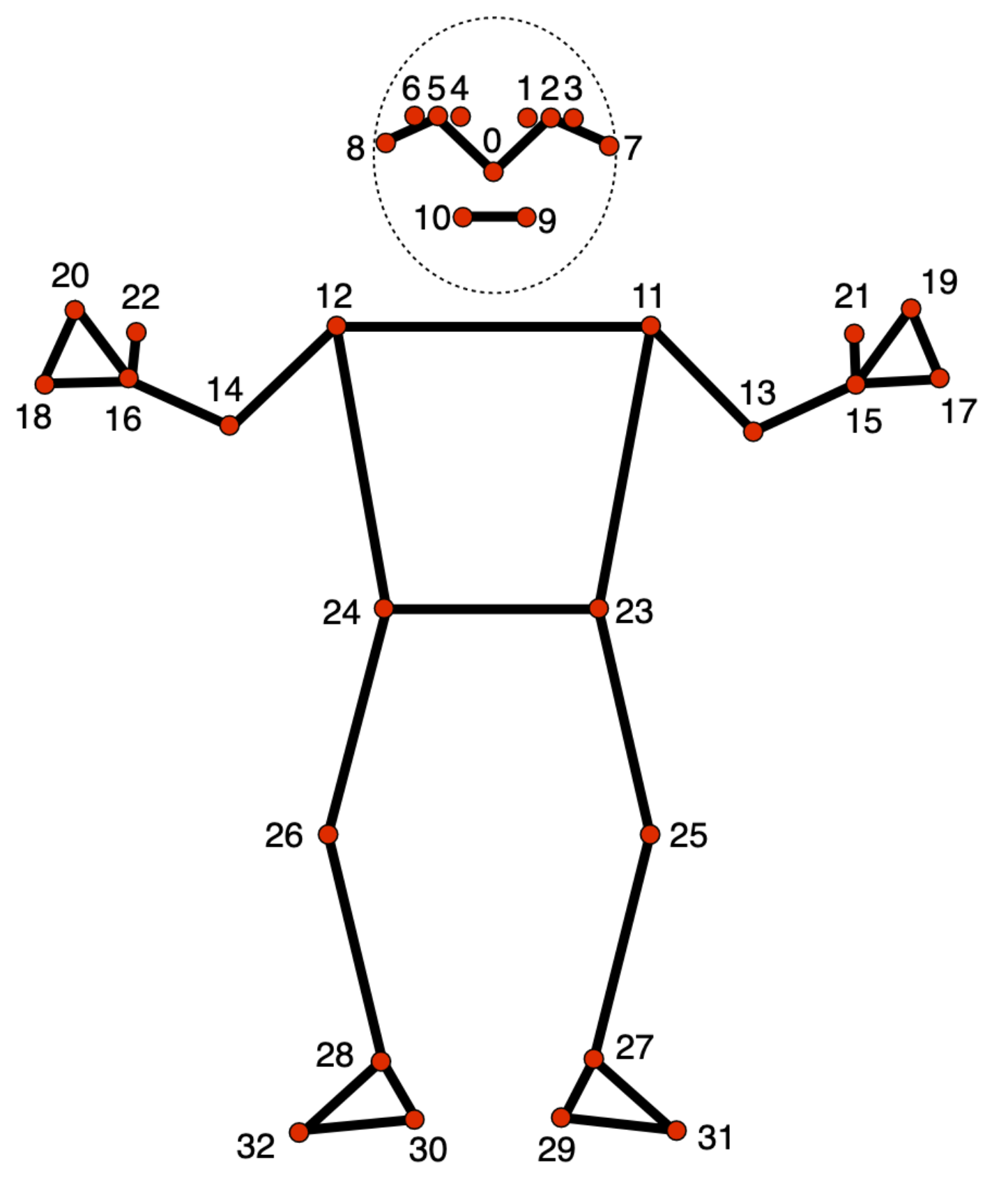
My application assumes a view of the user from the shoulders and above, so I decided to use three landmarks in my calculations: head, neck, and shoulders. Initially, I wanted to train a TensorFlow neural network on images of myself with “good” and “bad” posture, but I ended up going for a simpler calibration system instead. Rather than using regression to train a model, I wrote a simple script that uses a webcam and saves the angles (with respect to a fixed horizontal x-axis) of the three body landmarks along with “good” or “bad” labels when I click G (to indicate good posture) or B (to indicate bad posture) into a CSV file. Right before exiting, the script calculates the average midpoint between the “good” extreme and the “bad” extreme for each landmark angle. These three values are saved as thresholds for a “good” postural position turning into a “bad” position. This kind of calibration system is far less time-consuming and therefore more practical in an actual user application.
When the actual app is running, in every frame of the video stream, the MediaPipe model records the angle deviations away from the horizontal of each landmark. If the angle crosses the threshold for a certain landmark, it is considered bad (and given a value of 1.0). The final posture score is a simple average of the three angle deviations. Here’s an example with the shoulder landmarks:
posture_detection.py
posture_score = 0.0
total_weight = 0.0 # used to determine if none of the landmarks appeared
if l_sh[3] > MIN_VISIBILITY and r_sh[3] > MIN_VISIBILITY:
theta = _angle_from_horizontal(l_sh[0], l_sh[1], r_sh[0], r_sh[1])
# normalize deviation and add its weighted value to score
score += W_SHOULDER * min(theta / MAX_SHOULDER_ANGLE, 1.0)
total_weight += W_SHOULDER
This process is then repeated for the head and neck. The posture score contributes 60% to the overall focus score.
Habit #2: Wandering Gaze
The movement of our eyes is another subtle phenotypical quality we can observe to quantify distraction. My model accounts for iris position and stability over time, using the MediaPipe Face Landmarker task. In a very similar fashion to the posture model, I calibrated my gaze model to detect when a user’s eyes were closed, looking away, or flickering often. It uses the following weighted average to generate a final gaze score:
(0.7(on-screen frames / total frames) + 0.3(gaze_stability)) over the last 5s
The gaze score contributes 40% of the overall focus score.
Habit #3: Phone Usage
At this point, everyone knows that picking up your phone during a focus session is an easy way to get distracted. Having your phone next to you makes you more likely to pick it up. Even using the device just to check a quick notification can spiral into unintentional scrolling.
With how well-known of a problem phone addiction is, I wasn’t surprised to find during my research that solutions had already been created to combat this problem. In my project, I decided to use a preexisting open-source YOLO11 object detection model that had already been trained to detect a phone. As such, no training or calibration system was required. Object detection is a classification task, which means its scoring works differently from the other two models. Instead of a continous percentage score, the phone model outputs a Boolean value to indicate if a phone is present or not.
From my preliminary background research as well as my own intuition, I concluded that phone addiction was the most distracting factor out of the three habits I’m using. Therefore, I made the decision to have the presence of a phone immediately set the focus score to 0. The final focus score calculation is the following:
app.py
def calculate_focus(posture_pct, eye_pct, phone_pct):
if phone_pct == 100:
return 0
return int((0.6 * posture_pct) + (0.4 * eye_pct))
Results & Discussion
To assess performance, I ran the models on ten videos of myself that each had ten moments of distraction, categorized by my three metrics. In the end, the posture and gaze models achieved ~83% accuracy, and the phone model achieved ~91% accuracy.
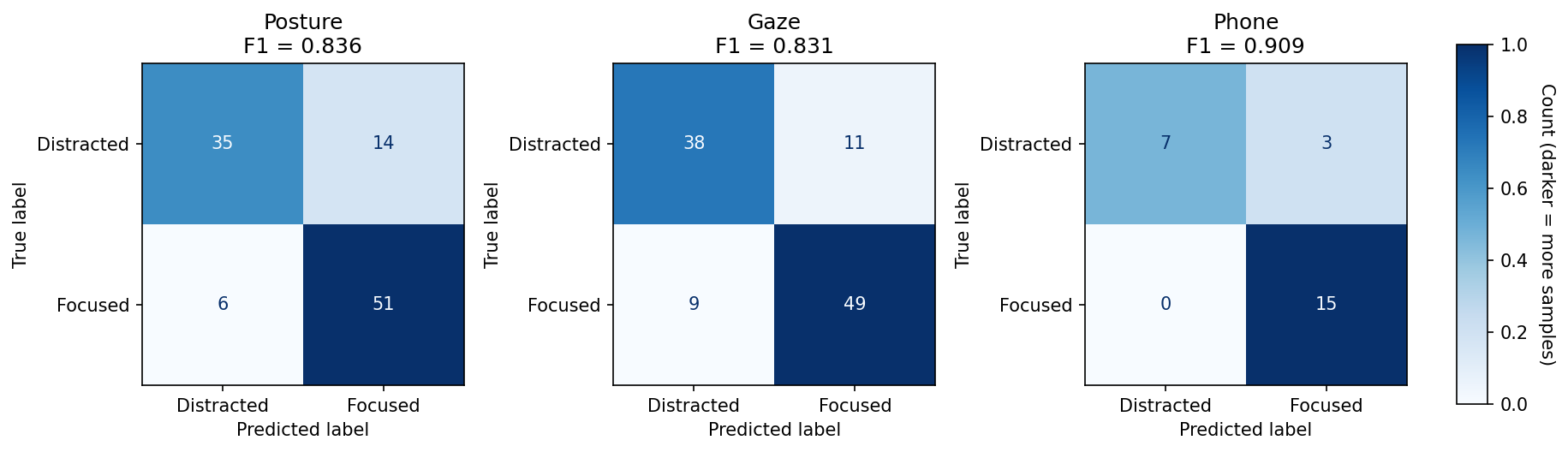
The results of the gaze model surprised me: I initially expected it would perform the worst, as wandering eyes intuitively feels much more subtle than, for example, an entire shift in your body. However, the gaze model was on par with the posture model, suggesting that computer vision can precisely capture subtlety.
These results are promising, but both my research and app development are still in their very early stages. In terms of research, I have several ideas for improving the performance of distraction quantification. For one, how might the calibration system be improved? Perhaps certain postural landmarks should matter more than others (e.g. a tilted torso is more indicative of bad posture than a tilted head). Will adding more landmarks improve performance, possibly at the cost of increasing overall complexity? Are there other metrics I can use, such as environmental factors?
Many questions remain, but among them all, there is one direction that I definitely will pursue as I continue to work on the project: collecting more data. My current results only speak to how the app performs on myself. They don’t tell me how the app might perform on different kinds of people with different kinds of focus behavior. To combat this issue, I plan to polish the project as an app and test it on tens to hundreds of neurologically diverse students (i.e. both neurotypical and neurodivergent).
Conclusion
This project has been a great introduction to computer vision for me, and in doing background research, I’ve learned a lot about different factors that can unknowingly distract us. I plan to continue experimenting with computer vision to push its capabilities even further. You can check out my code here, and if you’re interested in being a part of this project (by contributing data), feel free to reach out!